
Doing AI the hard way.
Data privacy is something that matters to me a great deal and I wanted to provide an option for customers interested in experimenting with current generation LLMs (Large Language Models) without sending information off-premise.

Before I jump too far into the (super) nerd-speak, I have a few small updates to share:
Updated Script Search
The previously discussed SQL queries for script search in the Call Theory Script Library have been updated to be even more efficient. Check out the raw queries in the library or use the Script Search utility built into your Call Theory Mission Control dashboard.
Thank you to the office hours regulars for the help in developing, iterating, and testing these queries with us!
- https://learn.calltheory.com/library/SQL/amtelco-find-broken-scripts/
- https://learn.calltheory.com/library/SQL/amtelco-search-scripts/
IS Scripting Intermediate Assessment
We made some updates to the Intermediate Assessment ahead of this Thursday's scripting session (where we will be finishing up Intermediate III and going through the assessment together.) If you need a refresher on Amtelco Contact-Based Architecture, make sure to join the session [requires our Technical Support ("Level Up") plan or a Managed Services contract.]
We need feedback for the Advanced sessions! What database, API, and MergeComm topics do you want to see? I want to cover some advanced topics and/or specific requests if possible - so send them our way! (email support@calltheory.com or hit reply)
Alright, let's get nerdy.
Bringing local AI to Mission Control
Last summer, I announced updates to the Call Theory Mission Control dashboard that included some rather ambitious plans for AI. Specifically, data privacy is something that matters to me a great deal and I wanted to provide an option for customers interested in experimenting with current generation LLMs (Large Language Models) without sending information off-premise.
Slightly over 7-month later, we've iterated and refined (changed) the approach 3-times and have arrived at what I would call a happy medium in capability and privacy. To be clear: there is no compromise - all AI features are done on-premise through a concept described as "inference at the edge."
Specifically, we are taking advantage of two key open-source projects that are well-maintained, battle-tested, and widely used: llama.cpp and whisper.cpp.
These projects are also generally compatible (if a little behind) with the Open AI API specification - which should allow expansion to things like the Azure Open AI Service or even Open AI's own API directly – eventually.
Whisper.cpp
Whisper is a model trained for audio transcriptions, originally released by OpenAI. Whisper.cpp implements the Whisper model. It's capable of running very lean: we can do on-server inference on most standard web-servers - with transcription speed approaching 10-20s per recorded minute when used in conjunction with background processing, rate limited queues, and strong caching.
The 10-20s transcription rate is based on an English-only "base" model with no language translation. Non-English capable models, especially when used with automatic translation will reduce the speed of transcription.
But we can take things a step further: by building these projects from source on the devices they are running on, we can take advantage of a technique called integer quantization - which uses an optimized model and may improve performance without updating hardware. (Not recommended on very small web servers as it's very CPU intensive even when limiting threads and processors.)
For most customers, this allows us to do modern AI-driven multi-lingual transcription and translation (with text highlighting) directly on their existing systems - and it's horizontally scalable behind the scenes for higher-volume scenarios.
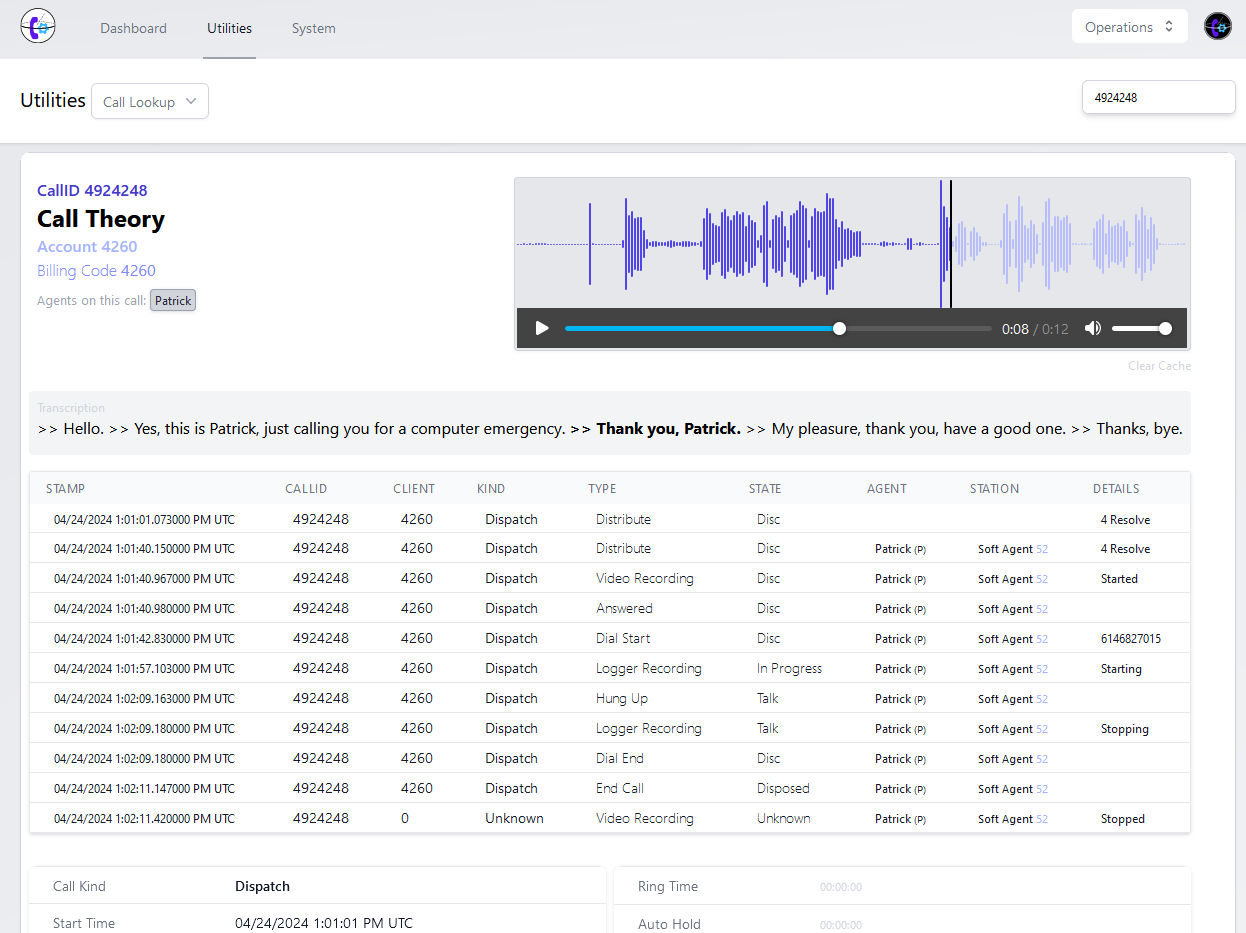
There are still some downsides on whisper.cpp for our use cases:
- Amtelco does not utilize stereo audio in their recordings, which is a requirement for using the built-in
--diarizeoption that ships with whisper.cpp. Diarization is what labels the speakers (or speaker changes) during transcription. - The
--tinydiarizeoption works great when compiled withtdrzsupport, but tinydiarize iteself only supports the currentsmall.enmodel - so we'd have to trade-off multi-lingual support and some transcription accuracy from the currentbaseoption. - We also have to use a compatible WAV file format for whisper.cpp, which is 16kHz, 16bit, 1-channel WAV files. (We handle this automatically in Mission Control regardless of your recording settings.)
I'm looking at using pynote.audio for speaker diarization as a potential alternative – wish me luck.
Llama.cpp
Llama.cpp has quickly spawned an entire ecosystem of personal and commercially available products around it. If you have the understanding to build, deploy, and manage llama.cpp, you can run your own LLMs from Meta, Google, Microsoft, and the greater open-source community - all on your own hardware.
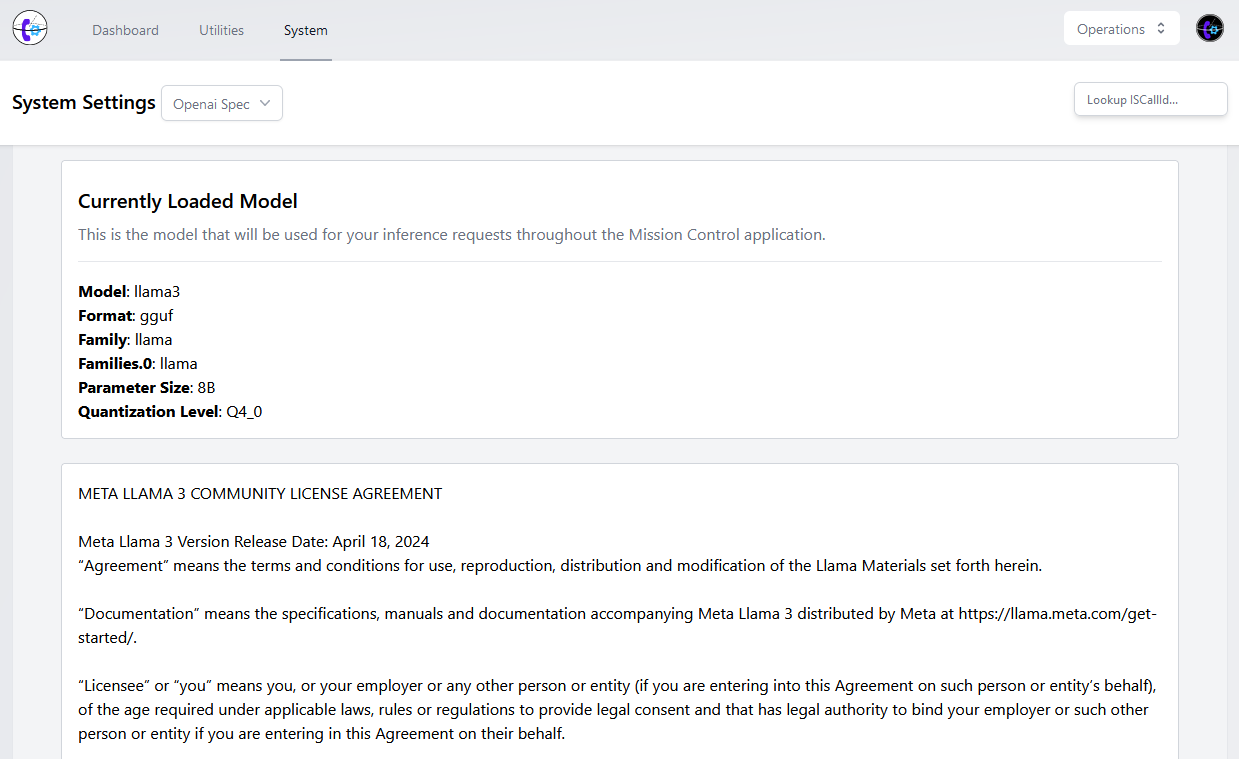
And that right there is the biggest problem - llama.cpp can't reliably co-exist on standard web server hardware like whisper.cpp can. These current generation multi-capable LLMs require heavy amounts of CPU, RAM, and especially GPU (VRAM) to make them work optimally - even for just one person - meaning that inference request scaling quickly becomes expensive when serving a website to multiple users (like the Call Theory dashboard.)
I imagine Open AI has such a close relationship with Microsoft for the funding they provide in the form of servers (and also the actual billions of dollars, too.)
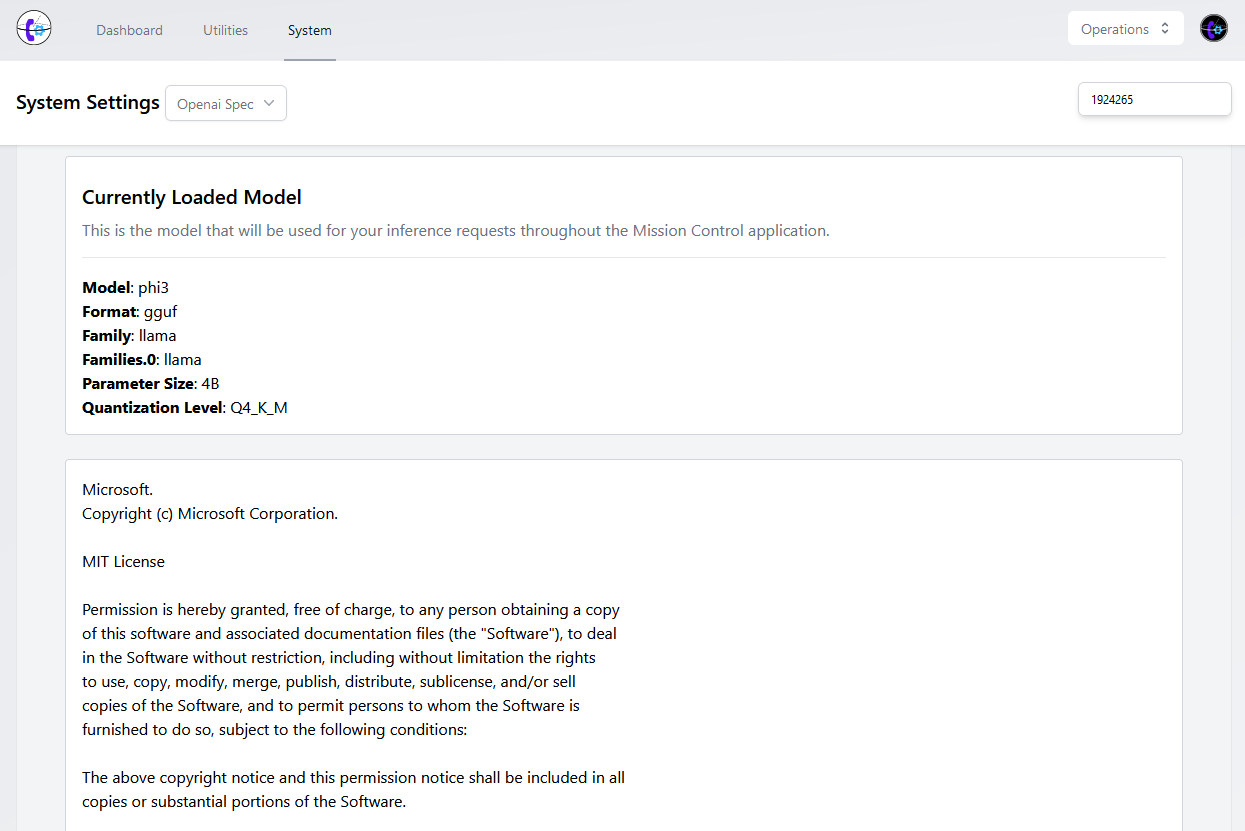
However, by leveraging llama.cpp, we can run our own Open AI API-spec compatible inference request endpoint using physical hardware, docker, virtual-machines, cloud-services, or any other combination of easily available Linux/docker systems in our own environments.
By offloading the model processing to another device, we can "bolt-on" locally-powered AI from the biggest and best models available directly into Mission Control - while still maintaining a cost-effective approach and full data privacy.
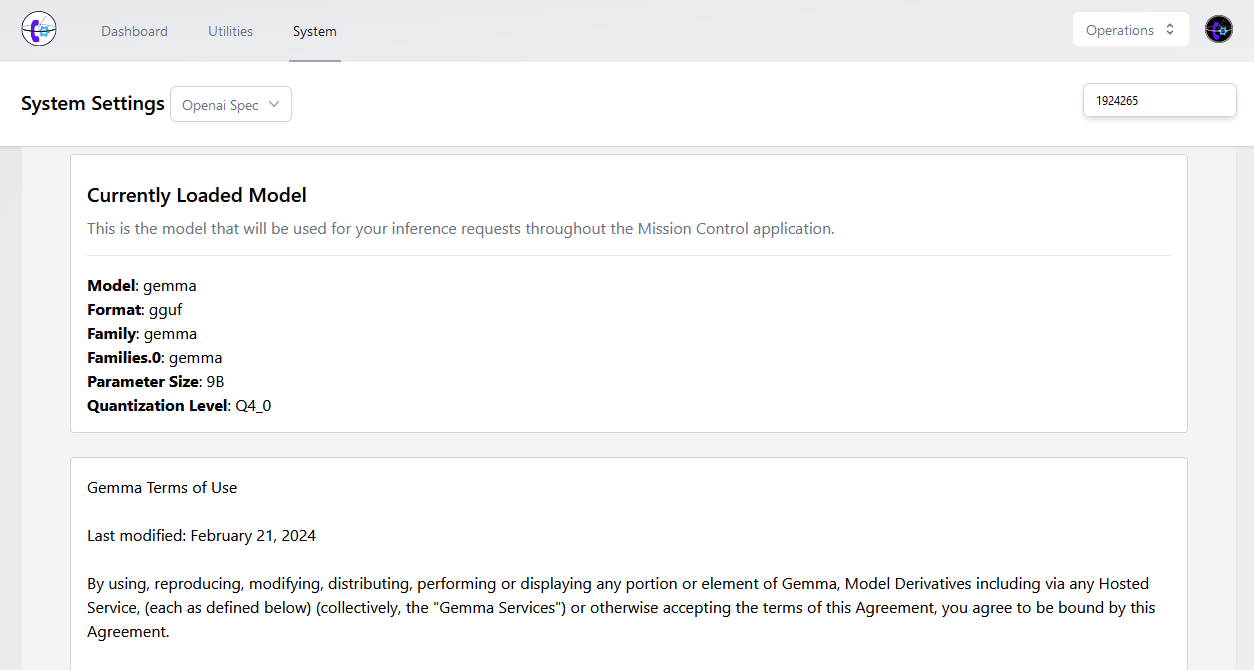
Now is a good time to start asking:
